
I wrote this post at about the same time Germany won the World Cup in Rio de Janeiro in 2014. There’s been a lot of moving and shaking in the world of exogenous ketones since then, not to mention soccer. Looking back on my post, I still consider it relevant in terms of what exogenous ketones possibly can (and cannot) do for performance. In this case, to see if exogenous ketone esters provide me a “boost” by allowing me to do the same amount of work while expending less energy (and work at a relatively lower VO2) compared to no supplementation.
I’m getting an increasing number of questions about exogenous ketones. Are they good? Do they work for performance? Is there a dose-response curve? If I’m fasting, can I consume them without “breaking” the fast? Am I in ketosis if my liver isn’t producing ketones, but my BOHB is 1.5 mmol/L after ingesting ketones? Can they “ramp-up” ketogenesis? Are they a “smart drug?” What happens if someone has high levels of both glucose and ketones? Are some products better than others? Salts vs esters? BHB vs AcAc? Can taking exogenous ketones reduce endogenous production on a ketogenic diet? What’s the difference between racemic mixtures, D-form, and L-form? What’s your experience with MCTs and C8?
Caveat emptor: the following post doesn’t come close to answering most of these questions. I only document my experience with BHB salts (and a non-commercial version at that), but say little to nothing about my experience with BHB esters or AcAc esters. But it will provide you will some context and understanding about what exogenous ketones are, and what they might do for athletic performance. We’ll likely podcast about the questions and topics above and cover other aspects of exogenous ketones in more detail.
—P.A., June 2018
§
Original publication date: August 14, 2014
Last year I wrote a couple of posts on the nuances and complexities of ketosis, with an emphasis on nutritional ketosis (but some discussion of other states of ketosis—starvation ketosis and diabetic ketoacidosis, or DKA). To understand this post, you’ll want to at least be familiar with the ideas in those posts, which can be found here and here.
In the second of these posts I discuss the Delta G implications of the body using ketones (specifically, beta-hydroxybutyrate, or BHB, and acetoacetate, or AcAc) for ATP generation, instead of glucose and free fatty acid (FFA). At the time I wrote that post I was particularly (read: personally) interested in the Delta G arbitrage. Stated simply, per unit of carbon, utilization of BHB offers more ATP for the same amount of oxygen consumption (as corollary, generation of the same amount of ATP requires less oxygen consumption, when compared to glucose or FFA).
I also concluded that post by discussing the possibility of testing this (theoretical) idea in a real person, with the help of exogenous (i.e., synthetic) ketones. I have seen this effect in (unpublished) data in world class athletes not on a ketogenic diet who have supplemented with exogenous ketones (more on that, below). Case after case showed a small, but significant increase in sub-threshold performance (as an example, efforts longer than about 4 minutes all-out).
So I decided to find out for myself if ketones could, indeed, offer up the same amount of usable energy with less oxygen consumption. Some housekeeping issues before getting into it.
- This is a self-experiment, not real “data”—“N of 1” stuff is suggestive, but it prevents the use of nifty little things likes error bars and p-values. Please don’t over interpret these results. My reason for sharing this is to spark a discussion and hope that a more systematic and rigorous approach can be undertaken.
- All of the data I’ll present below were from an experiment I did with the help of Dominic D’Agostino and Pat Jak (who did the indirect calorimetry) in the summer of 2013. (I wrote this up immediately, but I’ve only got around to blogging about it now.) Dom is, far and away, the most knowledgeable person on the topic of exogenous ketones. Others have been at it longer, but none have the vast experiences with all possible modalities (i.e., esters versus salts, BHB versus AcAc) and the concurrent understanding of how nutritional ketosis works. If people call me keto-man (some do, as silly as it sounds), they should call Dom keto-king.
- I have tried the following preparations of exogenous ketones: BHB monoester, AcAc di-ester, BHB mineral salt (BHB combined with Na+, K+, and Ca2+). I have consumed these at different concentrations and in combination with different mixing agents, including MCT oil, pure caprylic acid (C8), branch-chained amino acids, and lemon juice (to lower the pH). I won’t go into the details of each, though, for the sake of time.
- The ketone esters are, hands-down, the worst tasting compounds I have ever put in my body. The world’s worst scotch tastes like spring water compared to these things. The first time I tried 50 mL of BHB monoester, I failed to mix it with anything (Dom warned me, but I was too eager to try them to actually read his instructions). Strategic error. It tasted as I imagine jet fuel would taste. I thought I was going to go blind. I didn’t stop gagging for 10 minutes. (I did this before an early morning bike ride, and I was gagging so loudly in the kitchen that I woke up my wife, who was still sleeping in our bedroom.) The taste of the AcAc di-ester is at least masked by the fact that Dom was able to put it into capsules. But they are still categorically horrible. The salts are definitely better, but despite experimenting with them for months, I was unable to consistently ingest them without experiencing GI side-effects; often I was fine, but enough times I was not, which left me concluding that I still needed to work out the kinks. From my discussions with others using the BHB salts, it seems I have a particularly sensitive GI system.
The hypothesis we sought out to test
A keto-adapted subject (who may already benefit from some Delta G arbitrage) will, under fixed work load, require less oxygen when ingesting exogenous ketones than when not.
Posed as a question: At a given rate of mechanical work, would the addition of exogenous ketones reduce a subject’s oxygen consumption?
The “experiment”
- A keto-adapted subject (me) completed two 20-minute test rides at approximately 60% of VO2 max on a load generator (CompuTrainer); such a device allows one to “fix” the work requirement by fixing the power demand to pedal the bike
- This fixed load was chosen to be 180 watts which resulted in approximately 3 L/min of VO2—minute ventilation of oxygen (this was an aerobic effort at a power output of approximately 60% of functional threshold power, FTP, which also corresponded to a minute ventilation of approximately 60% of VO2 max)
- Test set #1—done under conditions of mild nutritional ketosis, while still fasted
- Test set #2—60 minutes following ingestion of 15.6 g BHB mineral salt to produce instant “artificial ketosis,” which took place immediately following Test set #1
- Measurements taken included whole blood glucose and BHB (every 5 minutes); VO2 and VCO2 (every 15 seconds); HR (continuous); RQ is calculated as the ratio of VO2 and VCO2. In the video of this post I explain what VO2, VCO2, and RQ tell us about energy expenditure and substrate use—very quickly, RQ typically varies between about 0.7 and 1.0—the closer RQ is to 0.7, the more fat is being oxidized; the reverse is true as RQ approaches 1.0

Results
Test set #1 (control—mild nutritional ketosis)
The table below shows the data collected over the first 20 minute effort. The 20 minute effort was continuous, but for the purpose of presenting the data, I’ve shown the segmental values—end of segment for glucose and BHB; segment average for HR, minute ventilation (in mL per min), and RQ; and segment total for minute ventilation (in liters).
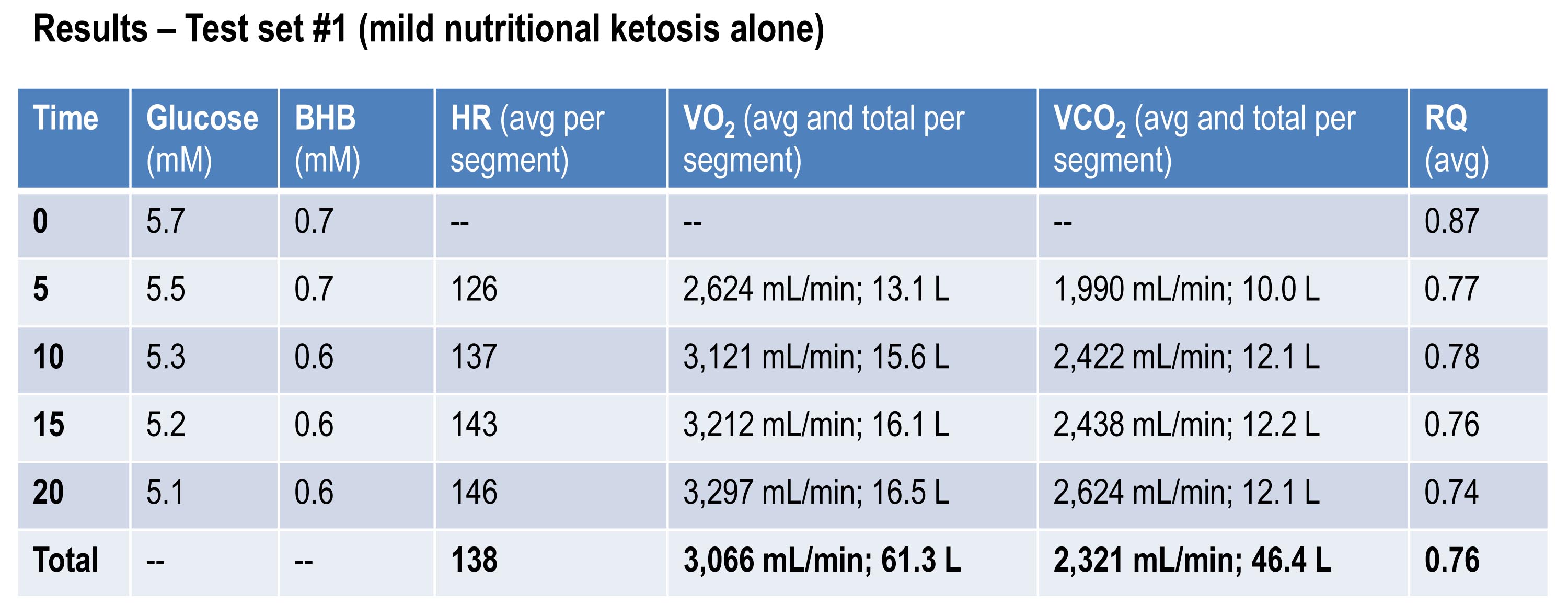
Glucose and BHB went down slightly throughout the effort and RQ fell, implying a high rate of fat oxidation. We can calculate fat oxidation from these data. Energy expenditure (EE), in kcal/min, can be derived from the VO2 and VCO2 data and the Weir equation. For this effort, EE was 14.66 kcal/min; RQ gives us a good representation of how much of the energy used during the exercise bout was derived from FFA vs. glucose—in this case about 87% FFA and 13% glucose. So fat oxidation was approximately 12.7 kcal/min or 1.41 g/min. It’s worth pointing out that “traditional” sports physiology preaches that fat oxidation peaks in a well-trained athlete at about 1 g/min. Clearly this is context limited (i.e., only true, if true at all, in athletes on high carb diets with high RQ). I’ve done several tests on myself to see how high I could push fat oxidation rate. So far my max is about 1.6 g/min. This suggests to me that very elite athletes (which I am not) who are highly fat adapted could approach 2 g/min of fat oxidation. Jeff Volek has done testing on elites and by personal communication he has recorded levels at 1.81 g/min. A very close friend of mine is contemplating a run at the 24 hour world record (cycling). I think it’s likely we’ll be able to get him to 2 g/min of fat oxidation on the correct diet.
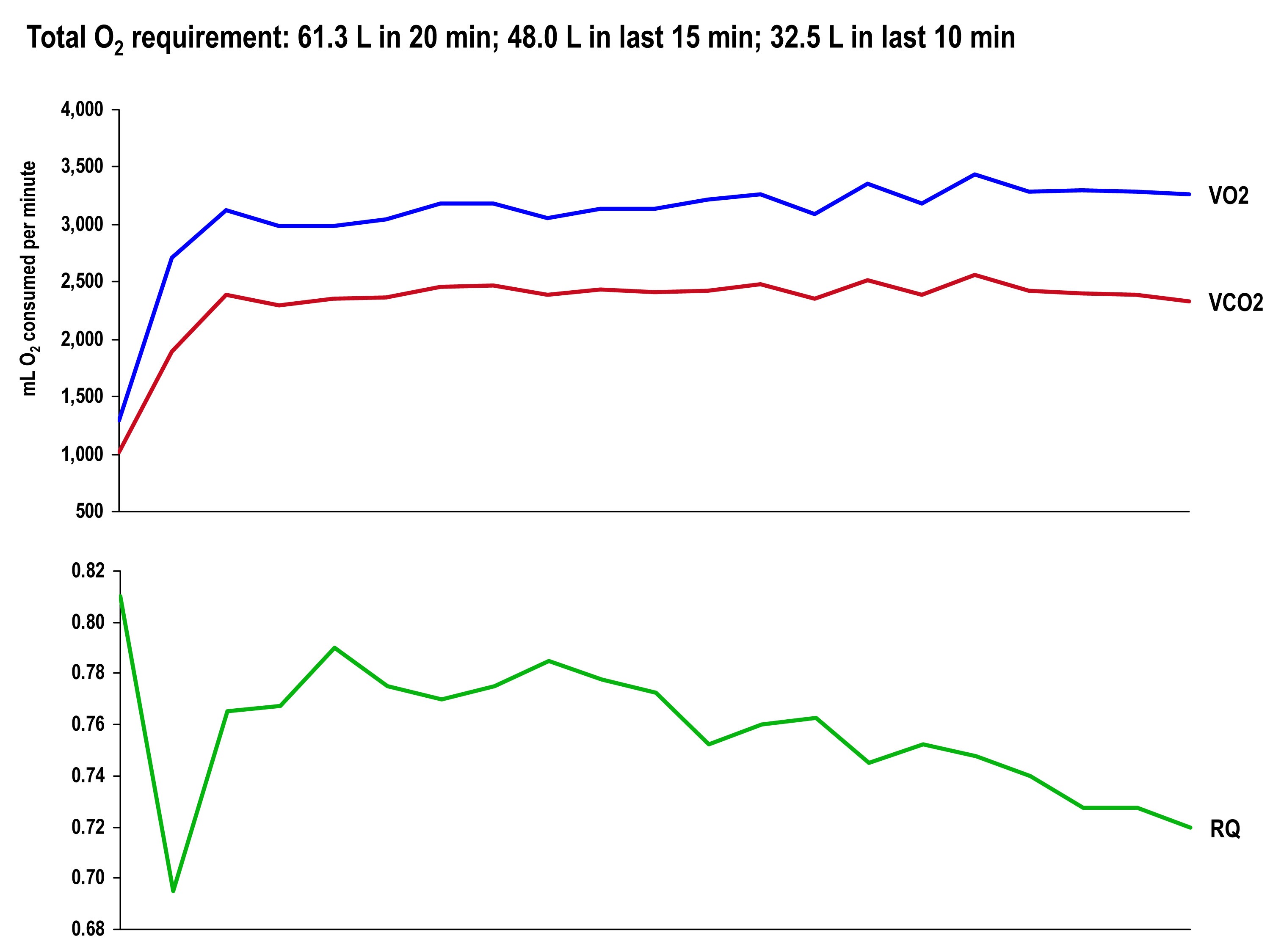
The graph, below, shows the continuous data for VO2, VCO2 (measured), and RQ (calculated).
Test set #2 (ingestion of 15.6 g BHB salt 60 minutes prior)
The table below shows the same measurements and calculations as the above table, but under the test conditions. You’ll note that BHB is higher at the start and falls more rapidly, as does glucose (for reasons I’ll explain below). HR data are almost identical to the control test, but VO2 and VCO2 are both lower. RQ, however, is slightly higher, implying that the reduction in oxygen consumption was greater than the reduction in carbon dioxide production.
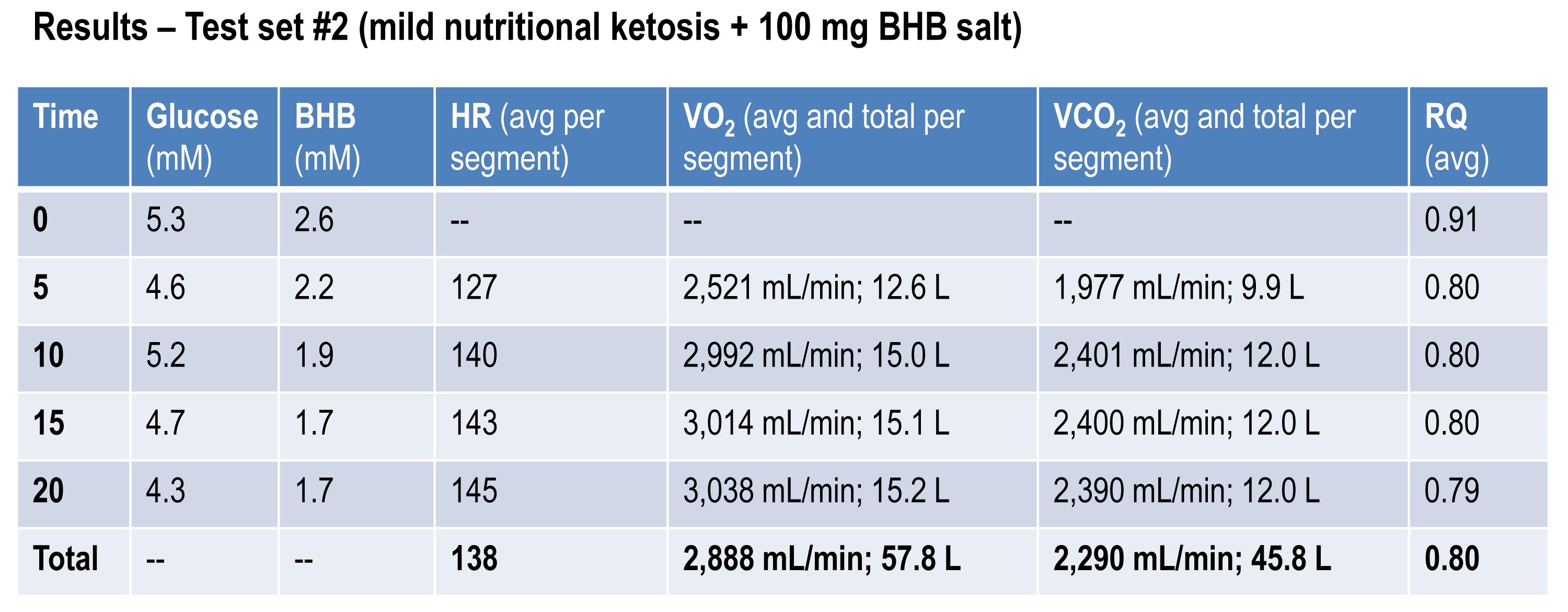
If you do the same calculations as I did above for estimating fat oxidation, you’ll see that EE in this case was approximately 13.92 kcal/min, while fat oxidation was only 67% of this, or 9.28 kcal/min, or 1.03 g/min. So, for this second effort (the test set) my body did about 5% less mechanical work, while oxidizing about 25% less of my own fat. The majority of this difference, I assume, is from the utilization of the exogenous BHB, and not glucose (again, I will address below what I think is happening with glucose levels).
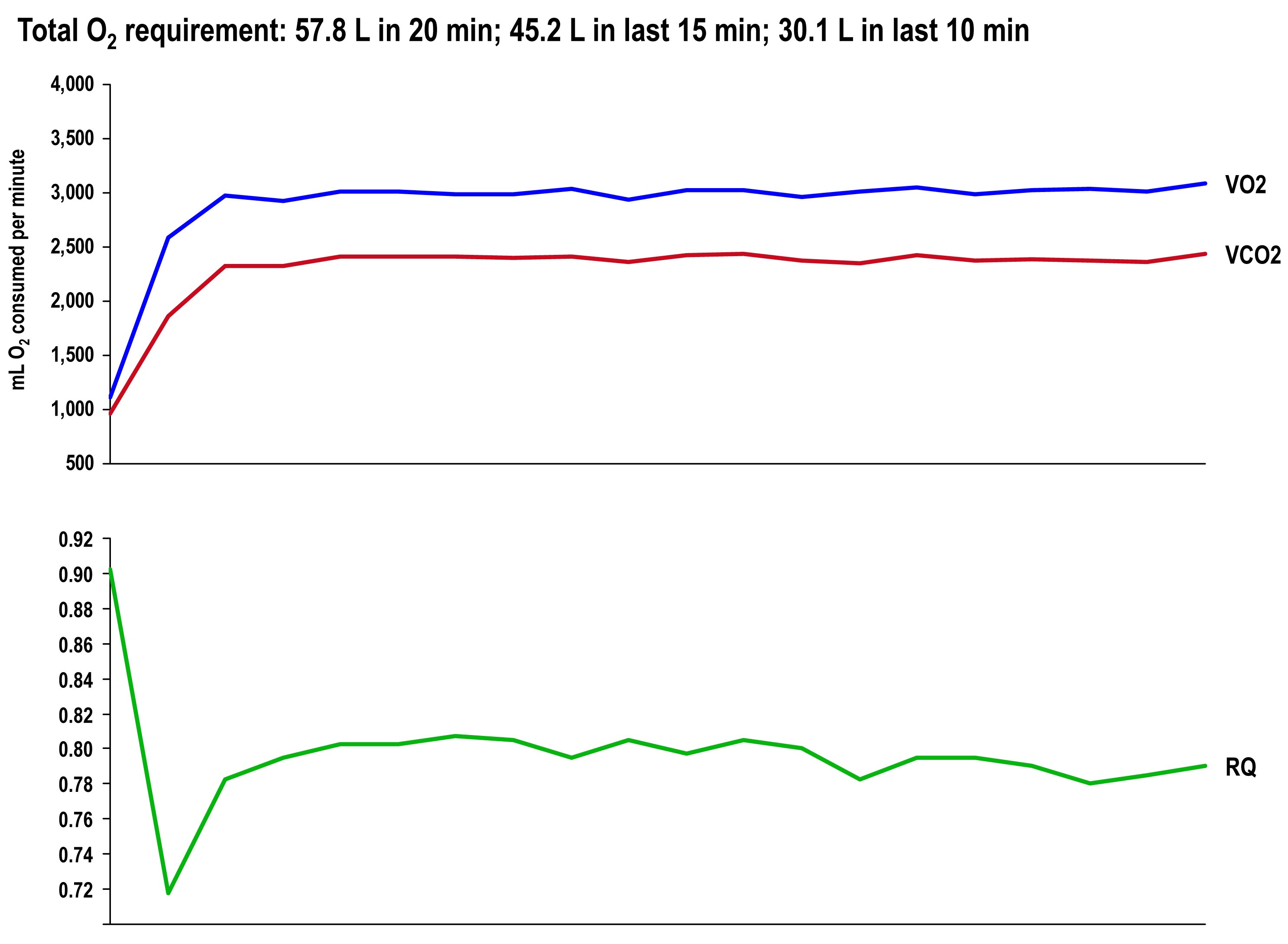
The graph once again shows the continuous data for VO2, VCO2 (measured), and RQ (calculated).
Side-by-side difference
The final graph, below, shows the continuous data for only VO2 side-by-side for the 20 minute period. The upper (blue) line represents oxygen consumption under control conditions, while the lower line (red) represents oxygen consumption following the BHB ingestion. In theory, given that the same load was being overcome, and the same amount of mechanical work was being done, these lines should be identical.
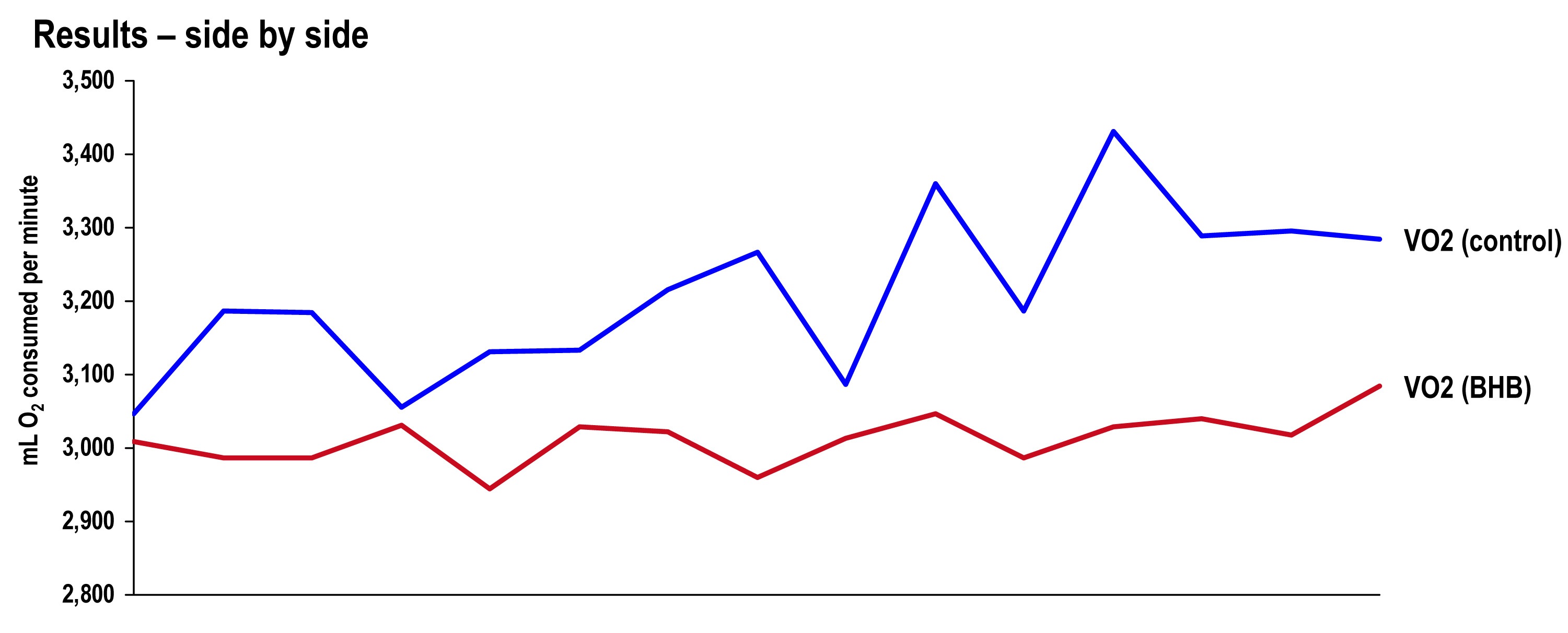
The hypothesis being tested in this “experiment” is that they would not be the same. Beyond visual inspection, the difference between the lines appears to grow as the test goes on, which is captured in the tabular data showing 5 minute segmental data.
Limitations
The most obvious limitation of this endeavor is the fact that it’s not an appropriately controlled experiment. Putting that aside, I want to focus on the nuanced limitations—which don’t impact the primary outcome of oxygen consumption—even if one were appropriately doing a real experiment.
- It’s not clear that the Weir coefficients used to estimate EE are relevant for someone in ketosis, let alone someone ingesting exogenous BHB. (The Weir formula states that EE is approximated by 3.94 * VO2 + 1.11 * VCO2, where VO2 and VCO2 are measured in L/min; 3.94 and 1.11 are the Weir coefficients, and they are derived by tabulating the stoichiometry of lipid synthesis and oxidation of fat and glucose and calculating the amount of oxygen consumed and carbon dioxide generated.) While this doesn’t impact the main observation—less oxygen was consumed with higher ketones—it does impact the estimation of EE and substrate use.
- In addition to the Weir coefficients being potentially off (which impacts EE), the RQ interpretation may be incorrect in the presence of endogenous or exogenous ketones. As a result, the estimation of fat and glucose oxidation may be off (though it’s directionally correct). That said, the current interpretation seems quite plausible—greater fat oxidation when I had to make my ketones; less when I got my ketones for “free.”
Observations from this “experiment” (and my experience, in general)
Animal models (e.g., using rat hearts) and unpublished case reports in elite athletes suggest supplemented BHB produces more ATP per unit carbon and per unit oxygen consumed than glycogen and FFA. This appears to have been the case in my anecdotal exercise.
The energy necessary to perform the mechanical work did not appear to change much between tests, though the amount of oxygen utilization and fat oxidation did go down measurably. The latter finding is not surprising since the body was not sitting on an abundant and available source of BHB—there was less need to make BHB “the old fashioned way.”
As seen in this exercise, glucose tends to fall quite precipitously following exogenous ketone ingestions. Without exception, every time I ingested these compounds (which I’ve probably done a total of 25 to 30 times), my glucose would fall, sometimes as low as 3 mM (just below 60 mg/dL). Despite this, I never felt symptomatic from hypoglycemia. Richard Veech (NIH) one of the pioneers of exogenous ketones, has suggested this phenomenon is the result of the ketones activating pyruvate dehydogenase (PDH), which enhances insulin-mediated glucose uptake. (At some point I will also write a post on Alzheimer’s disease, which almost always involves sluggish PDH activity —in animal models acute bolus of insulin transiently improves symptoms and administration of exogenous ketones does the same, even without glucose.)
In addition, the body regulates ketone production via ketonuria (peeing out excess ketones) and ketone-induced insulin release, which shuts off hepatic ketogenesis (the liver making more ketones when you have enough). The insulin from this process could be increasing glucose disposal which, when coupled with PDH activation, could drive glucose levels quite low.
If that explains the hypoglycemia, it would seem the absence of symptoms can be explained by the work of George Cahill (back in the day; see bottom figure in this post)—when ketone levels are high enough they can dominate brain fuel, even ahead of glucose.
Finally, these compounds seemed to have a profound impact on my appetite (they produced a strong tendency towards appetite suppression). I think there are at least two good explanations for this, which I plan to write about in a dedicated post. This particular topic—appetite regulation—is too interesting to warrant anything less.
Open questions to be tested in real experiments
- Are these results reproducible? If so, how variable are the results across individuals (by baseline metabolic state, diet, fitness)?
- Would the difference in oxygen consumption be larger (or smaller) in an athlete not already keto-adapted (i.e., not producing endogenous ketones)?
- Would the observed effect be greater at higher plasma levels of BHB (e.g., 5 to 7 mM), which is “easily” achievable with exogenous ketones?
- Would the observed effect be the same or different at higher levels of ATP demand (e.g., at FTP or at 85-95% of VO2 max)?
- Would the trend towards improved energy efficiency continue if the exercise bout was longer in duration (say, greater than 2 hours)?
- How will exogenous ketones impact exercise duration and lactate buffering?
- Why do exogenous ketones (both BHB and AcAc it seems) reduce blood glucose levels so much, and can this feature be exploited to treat type 2 diabetes?
- Are there deleterious effects from using exogenous ketones, besides GI side-effects?
- What are the differences between exogenous BHB and AcAc (which in vivo exist in a reversible equilibrium) on this particular phenomenon? (Work by Dom D’Agostino’s group and others have shown other differences in metabolic response and clinical application, including their relative impact on neurons.)
Photo by Alexey Lin on Unsplash

Very cool. Would seem to support the hypothesis that a ketogenic state is advantageous for high altitude conditions e.g. sherpas eating Yak butter. Presumably all the King Of The Mountains contenders will all be chugging BHB salts next year…!
Maybe they already are…
I would be more interested in seeing climbers attempting 8k summits switching to a ketogenic diet and/or consuming BHB salts.
I discussed my (subjective) experience cycling experience on Mount Evans (highest paved surface in NA) in NK in the video from the talk at IHMC.
I was trekking in Nepal two weeks before before the blizzard-avalanche. I had been eating LCHF and lost 20 lbs in about 3 mo. Going up hill at 12000 ft. challenged me. We met some trekkers who had just come over that mountain pass. Some hardy British mountain bikers were there too. It was hard to stay low carb on the available food. Yak steak is very tough!
Hi Peter and everyone.
I became fascinated with diet and ketones recently and found a ketone suppliment that I can attest is having some amazing results. It tastes great and I take it once a day. I have lost 8 lbs in 2 days and as you stated it does reduce appetite. I look forward to further posts and your research. Do you plan on expanding your research to ketones and diabetics and Alzheimer’s?
Hello Peter,
Company Pruvit have come out with an exogenous Ketone powder drink called KetOS,
I wonder what you think of it. Their ingredients are MCT oil and betahydroxybutyrate, natural flavors and Stevia.
Best,
Nilla
I’m not familiar with their product.
What source of BHB mineral salts did you use? This would be greatly informative for others looking to experiment with exogenous ketones. Specifically, a recent study published in Nature (https://www.ncbi.nlm.nih.gov/pubmed/25686106) implies BHB supplementation may be particularly helpful in patients suffering from disorders like gout. However, the supplement market being what it is, information about which suppliers provide reliable sources of BHB salts would be helpful.
in response to Martin’s comment – I have been climbing 14,000 peaks here in Colorado every year for the past 20 years. Last year I climbed Wetterhorn Peak and Uncomphagre while in ketosis (first time – in the past I’ve always “carb-loaded” prior to climbing).
I was not sure how it was going to go. But to my surprise, I summited without the usual dizzy spells, light nausia, light-headedness that I typically felt above treeline. On top of that, I didn’t feel like I needed to stop and snack. Didn’t grab any energy bars. I brought a bag of cashews instead and ate some at the summit. But energy was noticeably higher, both mentally and physically.
Hi Peter
I have been trying to keto adapt for 2 months
Using glucometer freestyle my ketone levels can range anywhere between 1.5 and 3 mmol ONLY if I am
Constantly eating fat every 2 hours.
If I don’t eat for more than 3 hours my ketones drop to .3
But when I wake up I am at .6
Is this normal if keto adapted??
I have 80% fat 15 % protein age 5% carbs break down of macros??
Also why do ketones go down after a weight session or even half hour bike ride ??
Please help
This is gonna fuel Durianrider’s fire lol.
Do we care? *grin*
absolutely not! Although, I do get a good chuckle out of his nonsensical videos
Cool. These tests are throwing up more questions than answers, but it’s something I’ll be most interested in over the coming years:
– https://highsteaks.com/forum/health-nutrition-and-science/ketone-supplements-esters-salts-557.0.html
The first thing anyone will want to know is if they are a decent enhancement, just how much of a stacking effect is there with nutritional ketosis and keto-adaptation – if any?
I’ve read/watched/listened to everything Dom has put out there, I reckon he’s 2015’s keto-sports guru, but the data on his war fighters and hyperbaric rats is still posing more questions than answers again.
For anyone wondering, the r/ketogains and r/ketoscience subreddits are on the forefront of VLC performance and the geeky stuff on how and why.
Always my intention, Ash…questions >> answers…
I could of swore that you said your next write up would be about quantifying insulin sensitivity like 3 blogs ago! But I must admit I really appreciated this one and am just thankful that you write this stuff for us! It has really gotten my mind thinking of the possibilities. Thanks.
I know, I know…it’s 3/4 written on my desktop. This tells you how difficult a topic IR is…I’m not sure how to write about it.
Thai is very interesting. Thank you.
As just an ordinary, aging Jill out here, I hope that some day you do find the time to write about the implications for treating dementia.
Is it only for Alzheimer’s dementia that the ketones may be helpful? Does anyone have any clues?
What about other forms of dementia, such as micro-vascular and frontal lobe dementia?
I still look forward to learning what you have to say about IR, and also medical interventions to lower LDL-p.
Thanks again.
Jane
I’ve already alluded to this in previous posts (and this one).
Thanks for this Peter, whenever you post something new I feel like a kid on Christmas morning…LOL
With my training I have found that my lactate threshold heart-rate from prior to being ketogenic to now is a difference of 30bpm higher being in ketosis, so I am very interested in knowing the difference from using exogenous ketones. i.e. testing LTHR before and after. Also me being a type 1 diabetic for people trying to use ketone esters or salt to boost them into ketosis, specifically overweight people that are insuin resistant, what would the implications be for overdosing and effectively putting them into a false state of ketoacidosis?
This test didn’t tell me anything about LT because the intensity was not high enough. One could make a theoretical arguments that NK, if MCT transporters are upregulated, could produce more lactate tolerance, but that could also turn out to be false, since it’s really the hydrogen ion, not lactate per se, that causes issues. (MCT transporters transport both BHB and lactate.)
I saw your Ted talk and am very impressed with your perspectives. I came across this on my Facebook news feed and have to admit I was lost at ‘exogenous ketones’. You may want to provide a better disclaimer that this is for medical students or whoever your target audience is, or at least a very clear summary of what this study actually proves. I love reading up on health and nutrition and recently switched to a low carb diet (not yet on a ketogenic diet), but couldn’t get what this was all about. Sorry!
Michelle… Peter’s target audience is whomever thinks all this cool! 🙂
(and possibly those who ride Pinarello bicycles! lol)
I agree with Michelle. This is Greek to me, but I am interested in a lay person’s version of these theories. I feel like my Type II diabetes is misunderstood, and that I may also be a victim of metabolic syndrome. This is what has led me to your blog, Peter. Your TedMed talk was very inspiring, and I understood most of it. Just checking around tonight to see what else you have put out here for us diabetics. I want to share this info with my doctors, but don’t think I can fully explain what you are telling us. Do you have a blog for others that are not medically trained.
Thank you for what you are doing. Someday, the world will be a better place because of you and your teams of rivals!
Best!
Exogenous = made outside the body while endogenous = made by the body.
I’m not a medical student. Never have been one.
I think your work is fantastic and we need more open minded doctors who are willing to look beyond the food pyramid. I just suggest identifying who the target audience should be here, as this is beyond the typical understanding of the general public. 🙂
I don’t have a target audience.
You sound like you’re familiar with a lot of Peter’s articles but, if not, it’s really worth reading them. A small number of them have been over my head, but then I’m not a hardcote athlete or in ketosis, and it’s more technical articles on ketosis I’ve struggled with. Oh, and the cholesterol series, but I probably can’t afford to get the right tests done regularly anyway.
I’ve read a number of these articles, and am very happy that we have a highly qualified doctor who is encouraging a ketogenic diet (and is proof that someone can thrive on it). Articles such as this one tend to be so technical that I couldn’t even understand the main point expressed (and aren’t any scientific studies supposed to have a clear hypothesis spelled out in the beginning?)
I guess my concern is that Peter has the opportunity to reach many, many people about the benefits of low carb diets. Without more explanations provided on the technical articles, many people (especially the ones who may benefit the most and need the most education), may tend to automatically scan over the article and decide that ketogenic diets are too complicated. Perhaps it’s my language degree , but I was taught to always know your audience and the implications that your writings will convey. Peter has the opportunity to effectively reach many people, and I encourage him to take advantage of that. 🙂
Michelle, I appreciate your point and am honored that you hold me in that regard. However, I’ve chosen a very different path than being a “diet guru” who writes to the median. My work is really taking place in two arena: first and foremost at NuSI (BTW–we’ll have a completely re-done website up in a few months). If you really want to understand what occupies me for 75 hours each week, spend some time there. The second place is in my clinical practice. If NuSI is a very public presence, my clinical practice is the exact opposite. Very small and very niche.
So where does that leave the blog? Well, to be honest, I shouldn’t be blogging for 2 reason: 1) I don’t have the time for it (168 hours in a week: 75 on NuSI, 10-15 on clinical work, family, training, sleep takes up the rest), 2) it’s creates confusion around my role as NuSI. No disrespect to “bloggers” (many of them are very good–better than I could ever be), but there should be no confusing what I do at NuSI with my personal blog.
So I guess there are only 2 options for me on the blogging front: none at all, or doing what I’m doing. I’m simply not willing to put any more time into this endeavor relative to the work I have to do.
Lastly, as other commentators have discussed, if you want everything served up in easy-to-digest blog posts, you’re unlikely to experience growth. I think it’s rewarding to be constantly challenged by new information.
Michelle – this is pretty heavy stuff, but I don’t think one needs to be a MD to understand it. I’m a computer programmer, and I’m glad this information is here and isn’t dumbed down; in other words, if it’s on Dr. Attia’s website, and I don’t know what it is, that just means I need to do my homework to understand it better. The whole point of trying to understand something better is to learn something you don’t already know.
It is challenging, because a person really needs to dig into what cells do, what metabolism is, and the fantastic biochemical orchestra that plays within the human body. As mentioned by several other commentors on this post, sometimes answering one question leaves you with more questions…
Hi Michelle,
I’m not an expert in any of this either and I understand your reaction. This is not “diet-doctor” stuff. The essence of what Peter Attia and Gary Taubes are doing is trying to get real Science applied to diet and nutrition. Check out Gary Taubes “Good Calories, Bad Calories” or his shorter “Why we get Fat”.
It’s really kind of disorienting because most people assume that Science must have all the big questions about things like what’s a healthy diet settled since they seem to be exploring all kinds of intricate details. Most doctors and nutritionist assume this too. If you google it you will come across a lot of MD’s and Phd’s insisting that it’s a matter of basic Physics (Laws of Thermodynamics) and calories are calories….and anyone suggesting otherwise is as scientifically clueless as a perpetual motion machine crank.
Getting to the point of understanding that these sincere experts might just be completely wrong takes some work. It is quite possible to do though these days. You just have to back up and google terms and ideas you don’t understand. Once you can read research papers with reasonable understanding this stuff really opens up. It does take some work to understand the critical ideas behind how Science SHOULD work, how experiments SHOULD be designed but it’s necessary because often the work that people are basing their judgements on is quite flawed.
I have the sense that this is a revolution in the culture of Science and Dr.Attia is giving us an unfiltered glimpse into the thinking. The practical diet part is pretty simple 🙂
BTW exogenous ketones are just ketones you swallow or take in from the outside rather than produce by metabolizing fat. This it high performance endurance athlete stuff. From the description it makes Cod liver oil taste like Cream and Stawberries.
Michelle, I would encourage you to read the articles here from the beginning. When you hit a word or concept you’re unfamiliar with, check it on google or wikipedia. After a few times of reading these, you may start to feel comfortable enough to read the underlying research. It takes time to be able to translate the sometimes science-babble in papers to human language, but after a while it becomes like speed-reading, and you can figure out what is irrelevant and what to look up or look into further, and which studies are poorly structured and can be ignored. That is the true gain of being here, learning to read the science for yourself. I think we all have personal stories here of how we were able to make informed decisions instead of relying on hurried or poorly informed doctors.
A personal example: A pregnant woman was diagnosed with gestational diabetes and told to take glyburide. A quick look at the research showed that glyburide has not been tested for use in pregant woman. That changed the decision to take it or not from an ignorant one to an informed one.
A recent amazing example is here: https://mosaicscience.com/story/diy-diagnosis-how-extreme-athlete-uncovered-her-genetic-flaw.
Don’t believe reading research is beyond the general public. It takes time to learn how, but it can be learned.
I’ve only two years of some college-level cell/genetics stuff under my belt, plus a semester on metabolic processes as a high-school exchange student (I studied lit and philosophy). After all these years, though, I’ve managed to forget everything. Nevertheless, Peter explains the key terms that might be unfamiliar to me. For example, his post “Ketosis – advantaged or misunderstood state? (Part II)” contains an argument that relies pretty heavily on interactions/comparisons between complex metabolic processes that go into producing fuel for cells. Yet the key terms are defined and placed into a context that makes it accessible for someone who didn’t attend a serious biochem course. Thus, I was still able to follow the general argument, even if I didn’t know how everything connects together. The post above is really interesting because it shows from start to finish a pretty neat concept for an experiment that treats an important issue for those of us who are involved in endurance sports. It’s an elegant, neat little unfiltered bit of experimental science that makes sense on some level. Again, he explained the key ideas without dumbing down the material. That’s something that at least this layperson values! Because when you’re thinking of changing fundamentally how you nourish yourself, it’s nice to see someone show their work when they’re advocating a view that goes against long-held conventions. I appreciate this.
Thanks, JK!
Fascinating stuff! Thanks for this
Question: how did it effect your appetite? Was your intake lower for a few hours? for a day? ‘
I wonder what would happen if you did this while endogenous BHB levels were higher
Can’t wait for your post on appetite, or the one on IR, supposed to be studying for boards but this is more fun 🙂
Huge suppression of appetite. I believe one of the first commercial applications of these products, once they can fix the taste, will be as a “diet supplement” that reduce appetite, rather than a performance booster.
Wow Peter – this is the Dr. D’Agostino on Jimmy’s recent AHS 14 panel??!?!? I sat there during that whole talk stunned while those guys talked about how difficult, impossible, unsustainable, and dangerous nutritional ketosis was, particularly because you might have to take a magnesium supplement. During that whole show I was thinking how much MORE you knew, Peter, than any of those guys. What did I miss? So sorry, I still think YOU’RE the keto-king. 😉
Also, Peter, lemme say that as a 40+ woman who tries pretty much to stay at 2.4 on the blood meter (which is hard of course because all the women who do this agree being on your period reduces your ketones no matter what you do because reproduction is a whole-metabolism event and not just a matter of a couple of hormones), my blood glucose is regularly between between 62 and 72, and I have to say I personally prefer the 62-65 range.
But this does mean I avoid having conventional doctors do blood tests on me lest they freak out and I also totally avoid oral tolerance tests so I don’t have to break ketosis for 3 days to fake the results. I press about 475 on the leg machine doing Superslow and definitely can get an extra rep out at 62 versus 70. 😉 Just an anecdote of the female experience. 😀
Best wishes.
Most of all I’m just so happy to hear that you’re doing Superslow!
And how are your slow workouts going on? You mentioned earlier you started it. Any good results? Any benefits for your riding?
Great results, especially given the time investment now vs. then. Also, less injury. I’m doing something very modified from the “typical” slow protocol, but the principles apply.
I was at AHS14 too and can’t remember the take home message being ‘unsustainable, dangerous…’ with particularly taking a magnesium supplement… (which, as a nutritionist, I recommend most people take….)?? If anything they promoted it as an adjunct therapy with traditional cancer therapy (which the panel discussion was about. I had dinner that night in a group that included Miriam and Ellen on the panel and they are very pro ketogenic. Both Colin Campbell and Dominic very knowledgeable and advocate ketogenic diet… unless I”m really confused by your post here? (which I could be! lol)
PS v impressive gym work btw.
I’m curious what glucose meter you are using to trust such accuracy between 62 mg/dl and 70 mg/dl? I have tried several glucose meters at the same time and I have tried using the same glucose meter with two blood checks and I can easily obtain a 20% variance, as published data supports.
Hi Peter,
Did you notice subjective changes in your effort during the tests? I’m guessing not.
I’m writing an essay on a mitochondrial disorder (MERRF) and am fascinated about cell-specific (or tissue-specific) energy thresholds and how different substrates being oxidized or fermented affects their survival. It appears very relevant to Alzheimer’s disease. Along the same lines, Peter (over at https://high-fat-nutrition.blogspot.nl/2014/07) has a cool post discussing “Neuronal Fuel and Function” which echoes the question: which fuel does this cell (or that cell) prefer in these circumstances?
Hope you find it interesting. [if you are not familiar with Peter – he’s a vet – and a very insightful dude]
Here is a short extract: “Ketones and lactate do not drive reverse electron flow through complex I. Glucose can. Palmitate certainly can. What you want from a metabolic fuel depends on the remit of your cell types. Neurons within the brain preserve information by their continued existence. This is best done by burning lactate or ketones. NOT glucose and, of course, not FFAs”
No, not really. 180 watts is low enough that perceived exertion differences would be too low to notice over such a short interval. If the test was done at 275 watts for 20 min, or 180 watts for 3 hours, I’m guessing I could answer the question one way or the other. I’m familiar with Peter’s work. Smart fellow.
I suffer mitochondrial myopathy and this is quite interesting. Is it possible to conclude that this will produce less ROS as a direct consequence of less oxygen being burned?
Great question. Add it to the list of things we need to understand.
Great question Luis. Peter, has anyone done any life extension research feeding ketone boosters to mice? Less oxygen used for metabolism should reduce oxidative stress on the electron transport chain. Less oxidation in mitochondria should reduce mitochondrial damage and might extend lifespan.
Not to my knowledge, but I have not looked specifically.
Peter, did you feel any “smarter”? I have been wondering about the brain boost from added ketones. Could someone taking an important test supplement with ketone drink and be smarter for the day??
I definitely feel (subjectively) “smarter” when BHB is high, but this is true even when I was fasting (one meal a day), so no sure t here is anything unique about synthetic ketones vs. naturally produced.
Peter, that is really really cool!
I Googled “what does KetoCal taste like?”, found on https://atkinsforseizures.com/forum/index.php?topic=9.0
“I remember the 3:1 was rather bland and had a fatty/slightly metalic taste to me. I do know a family who’s son wouldn’t drink it and they had to add liquid stevia to sweeten it before he would.”
Sounds considerably more appetizing that what you experimented with!
I have no idea what KetoCal is.
I have been doing ketosis for 6 months, and came across this, just this week, not public but I have been chating with them, prototype BHB mct oil, taste amazing, powder form, think they finally got it!! Have you or anyone heard of it?
https://pruvit.wistia.com/medias/akyqf0ja10
What did you end up mixing the ketone supplements with to make them less than awful tasting?
A cocktail of BCAA, soda water, and lemon juice.
Thank you for the information. I am struggling with how to use all your information to my best advantage. Having started Ultra-running about a year ago (1st 50K in Feb this year) I am trying to use more fat stores for fueling. Also my lean body mass to fat mass is not where I would like it. (eg 23%ish vs closer to 15%ish) Currently trying the avoidance of sugars etc. (avoidance means a lot lower than normal people ) I am a pretty smart guy, but I am not an MD. I am sure there are plenty of people in my situation. I wish there was an organization that could help one “hack” their diet to determine a healthy effective diet for that individual. From reading all your material you have taken a very scientific approach to this. Clearly different things work better for different people. Also you are giving out general information and not practicing medicine on this site. (I agree with the disclaimer and have read it, ) I don’t know how to quantify my progress and thus make course corrections.
Sorry struggling a bit to phrase the question. If you come across an organization that does such consulting that might be a good general blog. Or how to search for such an organization. I understand if it sounds like requesting medical advice or an endorsement. Not trying to put you in that “box”. In any event just keep up the fantastic work. I appreciate all of it.
Peter-
Thanks for another interesting / thought provoking post. I’m too old be doing this sort of thing to myself but I really appreciate your self-experimentation and the fact you share you data!
I also love your response “I don’t have a target audience”…. I guess a lot of people still don’t get the fact that this is your ‘personal blog’.
I’m just happy I happen to be like where your blog goes. 🙂
Keep it up…
Yup, pretty much a collection of musings. Maybe one day my kids will enjoy it. That’s about it.
I have been following Dr. Veech for several years, and have been in nutritional ketosis for almost 4 years to see if it helps a progressive peripheral motor neuropathy . To boost ketones I use MCT oil and AAKG (arginine alpha-ketoglutarate, which mostly tastes salty.) So I’m very interested in “Work by Dom D’Agostino’s group and others have shown other differences in metabolic response and clinical application, including their relative impact on neurons.”
I do have one question about your experiment. Since you did the control session first, followed immediately by the test session, would you have depleted your glycogen stores at all, and if so, would that have had an effect on the second session?
Unlikely, given my RQ from the first test. I barely used any glycogen at all. None of this is to say the first test didn’t impact the second, but if it did, I don’t think glycogen was the reason.
twitchyfirefly,
Your reasons for pursuing nutritional ketosis are inspiring! You mention in your post (2014) that you have been doing this for 4 years, so 5 years as of today. What are your personal observations so far?
Was your perceived exertion lower on the stuff?
This was only 60% of VO2 max, so for someone with my physiology, it would be hard to tell the difference. It would be interesting to examine at, say, 85-90% VO2 max.
Dr. Attia,
This may sound crazy, but do you happen to be visiting Phoenix? I swear I saw someone that looks like you today in a cafe and I almost wanted to come up and ask for your autograph ( your Got Grit blog is THE REASON I was motivated to truly change my life).
Nope…
Superslow is like the kind of think Fred Hahn recommends, I guess?
Yes, and others.