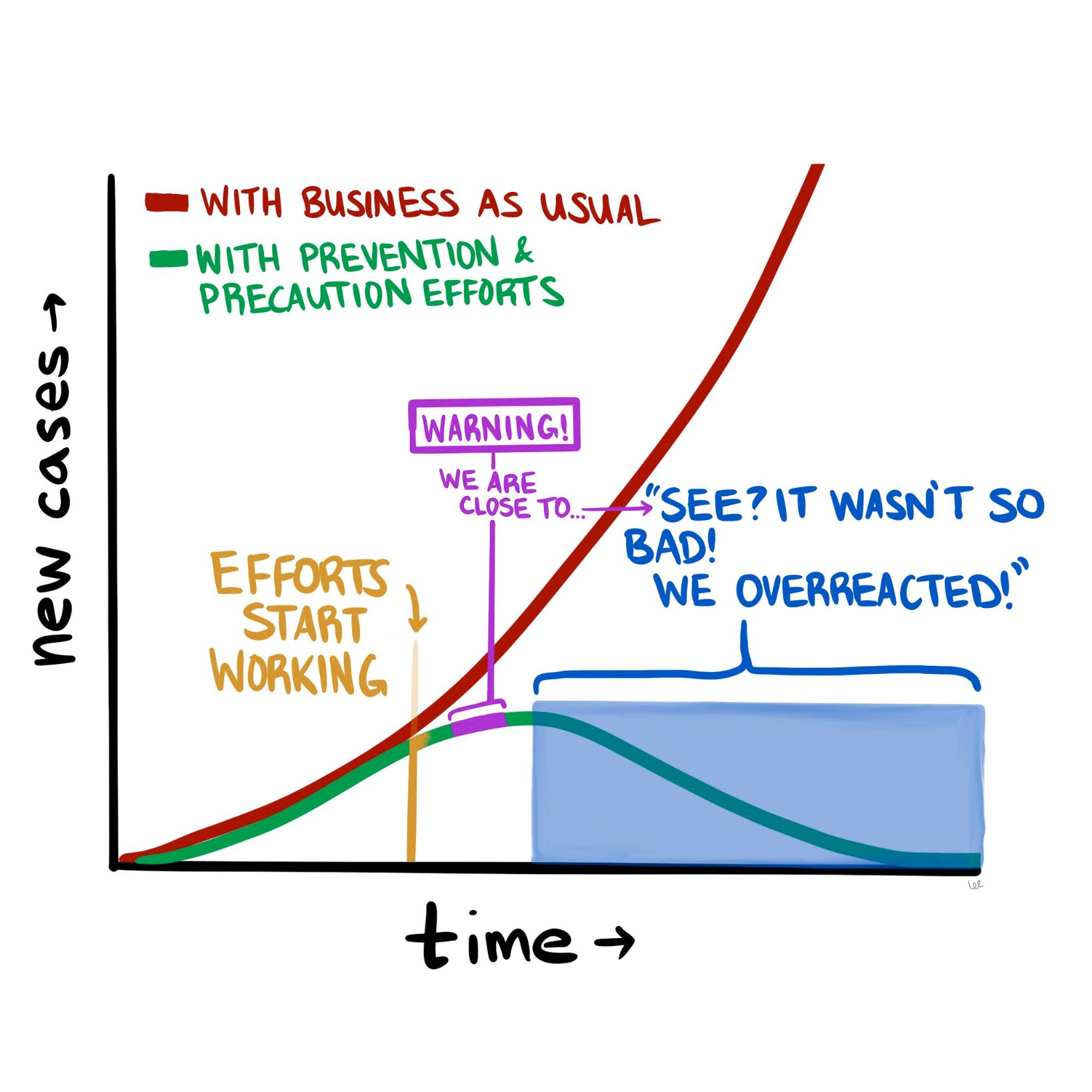
The COVID-19 pandemic is constantly evolving, but where we stand today looks a lot different than where we stood a month ago. The good news is that it doesn’t look nearly as catastrophic as it seemed in mid-March. The numbers of new cases and new deaths seem to be plateauing and even declining (slightly) in hotspots such as New York City. So now we are at a fork in the road, as the diagram above suggests. Do we continue the “lockdowns” in hard-hit parts of the country, to halt the further spread of the disease? Or do we begin to open up parts of the population (and economy), and inch back towards something resembling “normal?”
To contemplate, let alone answer, this question really digs into a much deeper question about the current state of affairs and how we got here. Are we in the somewhat favorable state we are in today because of how well we’ve contained the virus, how well we’ve “flattened the curve?” Or are we in this state because the SARS-CoV-2 virus is less deadly than we initially thought?
If possible, let’s try to have this discussion with as little emotion as possible. Instead, we should think about it through the lens of what we know about logic, supposition, and probabilities.
Let’s start with the early predictions that many people, myself included, found beyond frightening, but also at least somewhat plausible. Those predictions were produced by epidemiological models that used as inputs various properties assumed to be known about the virus, most importantly how readily it spread between people and how harmful it was to those who acquired it. And while these models varied wildly in their predicted outcomes—from 200,000 to more than 2 million deaths in the United States—they all have one thing in common, which is that the way things stand now, they appear wrong.
What follows is my current thinking about COVID-19 and the all-important models upon which we are basing our decisions, along with some suggestions of what we need to do to begin to break this logjam.
As I pointed out a few weeks ago, the models that predicted that ~60% of Americans would be infected and ~1.6 million of us would die in the coming 18 months were based on assumptions about SARS-CoV-2 and COVID-19 for which we had little to no data—specifically, the exact value of R_0 (i.e., how many new people each virus carrier infects, on average), the percentage of infected patients who will require hospitalization, and the fraction of infected patients who will die (i.e., infection fatality rate, or IFR). For the most part, we only know the case fatality rate (CFR) of COVID-19—that is, the number of confirmed positive patients who end up dying of the disease. This number is less helpful, because patients with the most severe symptoms (and probable bad outcomes) are more likely to be tested. So by definition the CFR must overestimate the IFR. This is a very important point, and it comes up again, so let’s be sure it’s clear before we proceed. The CFR is the ratio of deaths to known cases; the IFR is the ratio of deaths to total cases, known and unknown. If, as in the case of ebola, these are very similar, then using CFR for IFR will not take you too far off the mark. But what happens if the IFR is one-tenth of the CFR? In other words, what if the total number of unconfirmed infected persons is an order of magnitude larger than the number of confirmed cases?
We’ll come back to this. Let’s get back to the models.
The sensitivity of the models to one variable in particular is especially pronounced. If you want to experience this firsthand, play with the model described in this New York Times article, and see how even the smallest changes in the virus’s reproductive number, R_0, altered the outcome in seismic ways. For example, using the default parameters in place, simply changing the R_0 from 2.3 to 2.4 triples the projected number of infected people from 10 million to 30 million. Think about that for a second. A seemingly negligible increase in the per-person rate of transmission leads to a 3x difference in total infections! (According to the model, anyway.) And what if you assume R_0 is a “mere” 2.1 (still a very contagious virus, by the way)? Fewer than 1 million Americans could expect to be infected. Tiny changes in inputs make the difference between a catastrophe and a minor speed bump. As someone who used to make a living building models—and as someone who has been humbled by them (albeit for mortgage defaults, not pandemics)—I can tell you that when you have a model that behaves this way, you need to be even more cautious than you otherwise would, and should, be with any model.
Projections only matter if you can hold conditions constant from the moment of your prediction, and even then, it’s not clear if projections and models matter much at all if they are not based on actual, real-world data. In the case of this pandemic, conditions have changed dramatically (e.g., aggressive social distancing), while our data inputs remain guesswork at best.
So, absent actual data, assumptions about these parameters were made—guesses, actually—but these assumptions lacked the uncertainty that we would expect from actual epidemiological data. What do I mean by lacking in uncertainty? Imagine that you are trying to estimate the number of acorns in your neighborhood by the end of next year. You build a model that factors in many variables, such as the number of oak trees, the weather, and so on, but in the end you realize the model is most sensitive to the number of squirrels in your neighborhood and how much their weight changes over the winter. You could guess at those parameters. Or you could spend time measuring them and using actual data as the inputs to the model. If you choose the former, you are merely entering a value (or values) for the respective parameters. That’s your best guess. But if you choose the latter, you are probably not using a single, accurate number—it’s quite a project to count squirrels with any accuracy. Instead, you must use a probability distribution for the input.
Why? Because you are accepting the inherent uncertainty of the situation: Actually trying to count each and every squirrel, which would require an enormous effort and likely some draconian tactics, would still not yield a completely accurate number. It might be better to just count the squirrels on, say, one block, and multiply by the number of blocks, and adjust for other factors, and come up with a likely range of squirrel population numbers. This is not a pure guess, but neither is it an exact number, because when it comes to squirrels, and viruses, it is almost impossible to know their actual prevalence with total certainty.
As I learned when I was modeling mortgage credit risk, an A-plus model accounts for this inherent uncertainty by allowing you to use ranges of numbers (or better yet, a probability distribution curve) as inputs, instead of just static values. Instead of assuming every person who originated a mortgage in a particular tranche of risk has $3,000 in cash reserve for a rainy day, you might assume a probability distribution of cash reserve (and therefore financial runway prior to defaulting) that was normally distributed (i.e., shaped like a bell curve) around $3,000 or if you were really slick you’d get actual data from the Treasury or a consumer database that would give an even more nuanced probability function.1In reality, such a number would not be normally distributed because it is bounded below by zero, but technically has no upper bound, so the distribution of cash reserve would be skewed—and all of this could be approximated or measured. Obviously, knowing how much cash a person has in reserve is a very important factor in determining how long they will pay their mortgage in the event of an economic shock. (And rest assured that the major banks are furiously adjusting their own models in this regard right at this very moment.)
Back to our squirrels. If we choose to do the work and use actual data to inform our model, rather than our best point estimate, the input would be accompanied by a confidence level, or a measure of how certain you are that the correct answer lies in your range. Again, an A-plus model would have the ability to process the “number of squirrels” as 5,634 to 8,251 with 95% confidence. (For a quick primer on what it means to be “95% confident” in your guess, please take a few minutes to do this exercise). A B-minus model (or worse) would take one single number in for the number of squirrels and, worse yet, it would assume you have 100% certainty in that number. When a B-minus model gives you an “answer,” it has no range. It communicates no uncertainty. You have no ability to assign confidence to it, statistical or otherwise.
Unfortunately, most of the models used to make COVID-19 projections were not built to incorporate uncertain data, nor were they capable of spitting out answers with varying degrees of uncertainty. And while I suspect the people building said models realized this shortcoming, the majority of the press is not really mathematically or scientifically literate enough to point this out in their reporting. The result was a false sense of certainty, based on the models. I should emphasize that the models were off target not because the people who made them are ignorant or incompetent, but because we had little to no viable data to put into the models to begin with. We didn’t have several months to painstakingly count the squirrels. We didn’t even have a method for counting them. The best we could do was make guesses about squirrels, which we had never seen before, based on our understanding of bunnies and mice.
So, what does the future look like from where we stand today, versus a month ago? Do we have the same dire view of the future? Or has it changed?
Mine has changed. Quite a bit, actually. Today I suspect American fatalities from COVID-19 will be more in line with a very bad, perhaps the worst, season of influenza (The last decade saw flu deaths in the U.S. range from 12,000 to 61,000, so you can imagine how much variability exists). This suggests COVID-19 will kill tens of thousands in the U.S. this year, but likely not hundreds of thousands, and definitely not millions, as previously predicted.
What accounts for my different outlook today? There are really only two first-order explanations for why I can say the early projections were incorrect:
- Either the models were wrong because they incorrectly assigned properties about the biology of the virus pertaining to its lethality and/or ability to spread, or
- The models were correct, but as a society we changed our behavior enough in response to the threat of the virus to alter the outcome. In other words, the models were correct in assuming R_0 was high (north of 2.25 and in some estimates as high as 3), but aggressive measures of social distancing reduced R_0 to <1, thereby stopping the spread of the virus, despite its lethal nature.
It is, of course, most likely to be a combination of these two conditions; call them Case I and Case II, respectively. They are not mutually exclusive, either. In fact the jugular question today is how much of each? Is it 90/10, 10/90, or 50/50? If the predictions were wrong because we misunderstood the biology of the virus (overstating its risk significantly)—that is, we’re in a mostly Case I scenario—then we may start the process of thoughtful reintegration. If the predictions were wrong because we understood the biology, modeled it correctly, and appropriately put into place extreme social distancing measures—that is, we’re mostly in a Case II scenario—then we need to continue strict social distancing until we have effective treatments. Otherwise we risk a resurgence of disease that could dwarf what we are currently experiencing.
I have thought very long and hard about how to differentiate between these two scenarios—Case I vs Case II—and in my opinion the most effective and expeditious way to do so is to determine the seroprevalence of asymptomatic people in the major cities in the U.S., starting with the epicenter, NYC. In other words, find out (via blood testing for antibodies) how many people were already infected that weren’t captured as “confirmed cases.” Ideally, we would be able to do that by testing every single person in the city (that is, counting all the squirrels). But because that is infeasible, we should test as large a cross-section of the asymptomatic NYC population as possible, and extrapolate from the results. Either way, we need to broadly test people with no symptoms, which is something we have not done so far in an area hit as hard as NYC.
These data are enormously important. If the asymptomatic prevalence in NYC is 5%, meaning 5% of asymptomatic persons in NYC have been infected, while 95% have not, it would imply the IFR for COVID-19 is approximately 2.4%. This is a deadly virus, approximately 25x more deadly than seasonal influenza in NYC.2Bear in mind that the widely reported CFR of 0.1% for influenza runs into the same problem we have with COVID-19: the IFR of seasonal influenza may be a fraction of its CFR. It would also imply that efforts to contain the spread have been effective and/or the R_0 of the virus (the reproduction number) is much lower than has been estimated (2.2 to 2.6).
Conversely, if the asymptomatic prevalence in NYC is, say, 30%, it would imply that the IFR for COVID-19 is approximately 0.4%. This is a far less deadly virus than previously suggested, although still approximately 4x more deadly than influenza in NYC.3And it’s not an apples-to-apples comparison because healthcare workers are immunized, albeit modestly, to influenza, as are many high risk people, while no one is immunized to SARS-CoV-2. When the dust settles, I suspect much of the spread of this virus will likely trace to nosocomial sources that would normally be less in the case of influenza. It also implies that the disease is far more widespread than previously suggested. If 30 percent of New Yorkers have been infected, then efforts to prevent its spread have not been very successful, but NYC is approaching herd immunity (see figure and table, below, which show the relationship between R_0 and herd immunity).
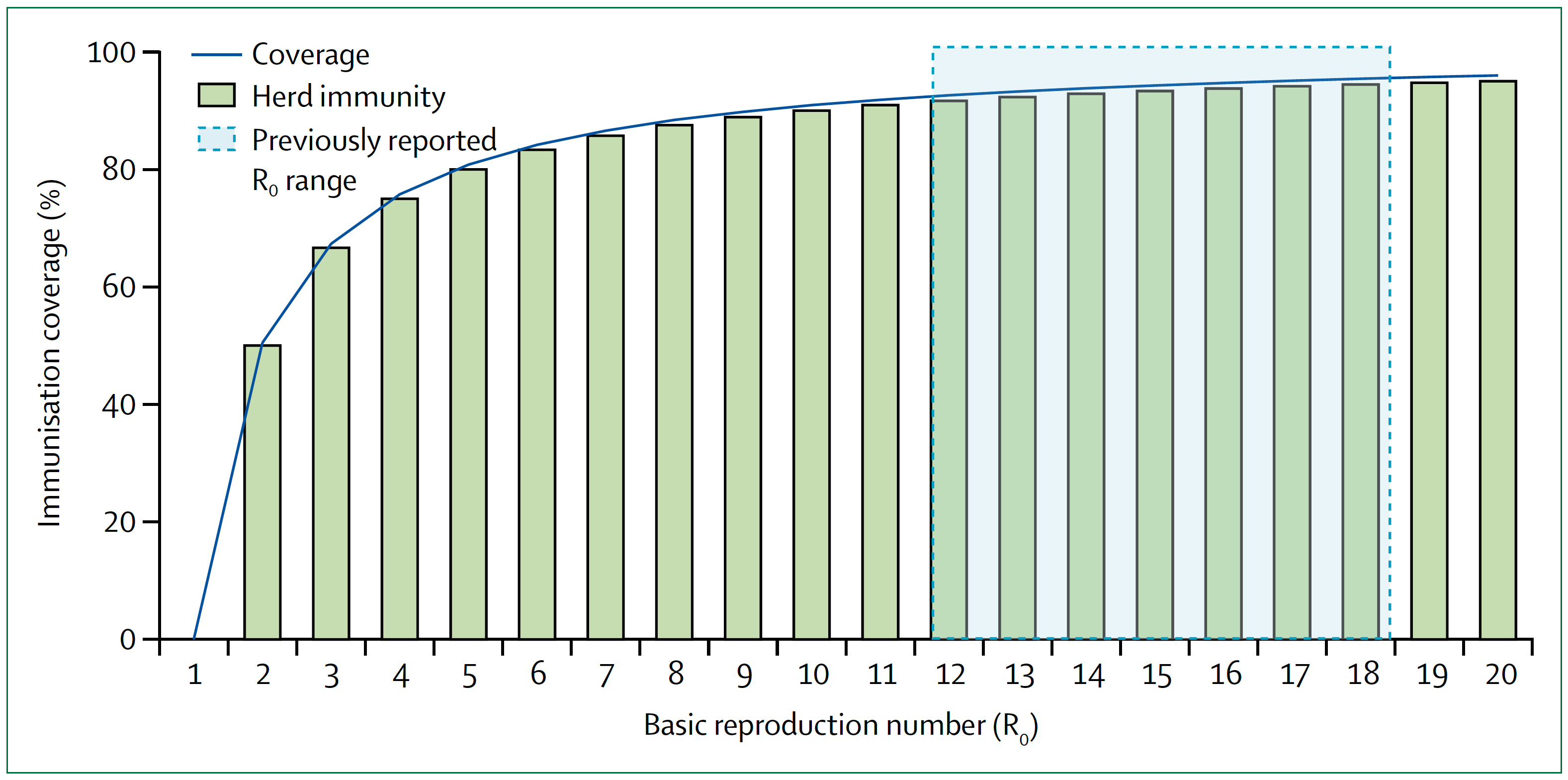
Figure. Measles basic reproduction number, herd immunity, and coverage. As R_0 increases, higher immunisation coverage is needed to achieve herd immunity. Blue zone indicates the R_0 estimate for measles of 12–18. In the context of COVID-19, notice the higher the R_0, the higher the threshold to reach herd immunity. Image credit: Guerra et al., 2017
§
Table. Estimated R_0 and herd immunity thresholds for different infectious diseases.
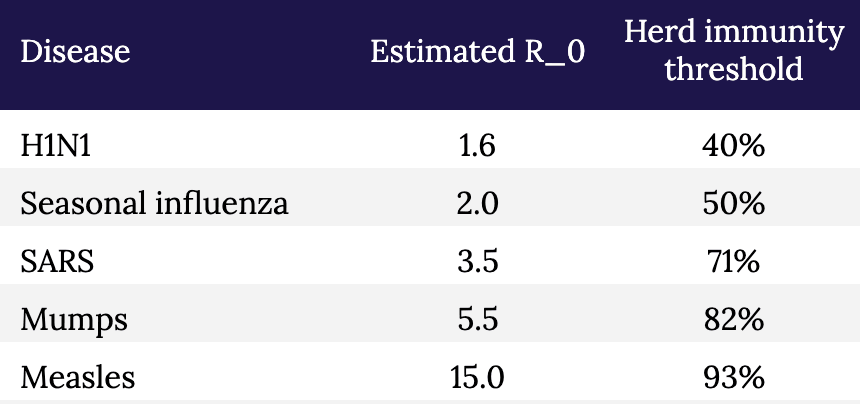
The sooner we know how the virus behaved in the most hard-hit city in the country (and likely the world), the sooner we can start making better decisions with at least some modicum of confidence, versus blind certainty in models that don’t have the humility to incorporate a margin of error or degree of uncertainty. And of course, the models should also be to take into account regional and demographic variation. It seems likely that in some areas we will need to remain cautious, while in others less so; with some people we will need to remain cautious, while in others less so. For example, the virus clearly seems to spread more rapidly (meaning, the R_0 is higher) in NYC than in, say, Utah. And clearly some people are much more susceptible to major illness and death than others.
Testing broadly, especially asymptomatic people, to better estimate the true fatality rate is an essential part of any strategy to move forward. Doing so, especially if we can add more elaborate tools for contact tracing, can give us real data on the most important properties of the virus: how rapidly it spreads and how harmful it is to all people, not just the ones we already know about. And that data, in turn, will help us build better and more accurate models.
But we shouldn’t look at models to give us the “answers.” How many people will be hospitalized, how many people will die, and so on. That’s our natural, lazy inclination. Instead we should look to the models to show us how to change the answers. That’s why they are important, and why it is so important that those models a) accept uncertainty, and b) are based on the best data we can obtain. The model is not a prophet. It is simply a tool to help us understand the biology of what is happening, and to help us figure out what we have to do next.
Go back in time to March 1: Knowing what we knew then, quarantine and extreme social distancing was absolutely the right thing to do because we didn’t even know what we didn’t know, and we needed to slow the clock down. It was like taking a timeout early in the first quarter after your opponent has just scored two lightning touchdowns in a rapid succession. It may have seemed unnecessary to some, but we needed to figure out what was going on.
The mistake was not taking the timeout. The mistake was not using our timeout to better understand our opponent. We failed to scale up testing and gather the essential information outlined here that would have helped us create better, more nuanced and hopefully more accurate models, rather than having to essentially guess at our data inputs (and hence at the outcomes). Now, six weeks later, we are still in the dark because we didn’t do the broad testing that we should have done back then. We still don’t know fully how many people contract this virus and come out relatively unscathed.
We still have time to reduce the health and economic damage done by this virus and our response to it, but we can’t waste another timeout sitting around looking at each other and guessing.
– Peter